e-GIF is Electronic Government Interoperability Framework, which is a Government Enterprise Architecture portraying the overall blueprints of how government is structured and determines how government agencies can effectively achieve their desired objectives
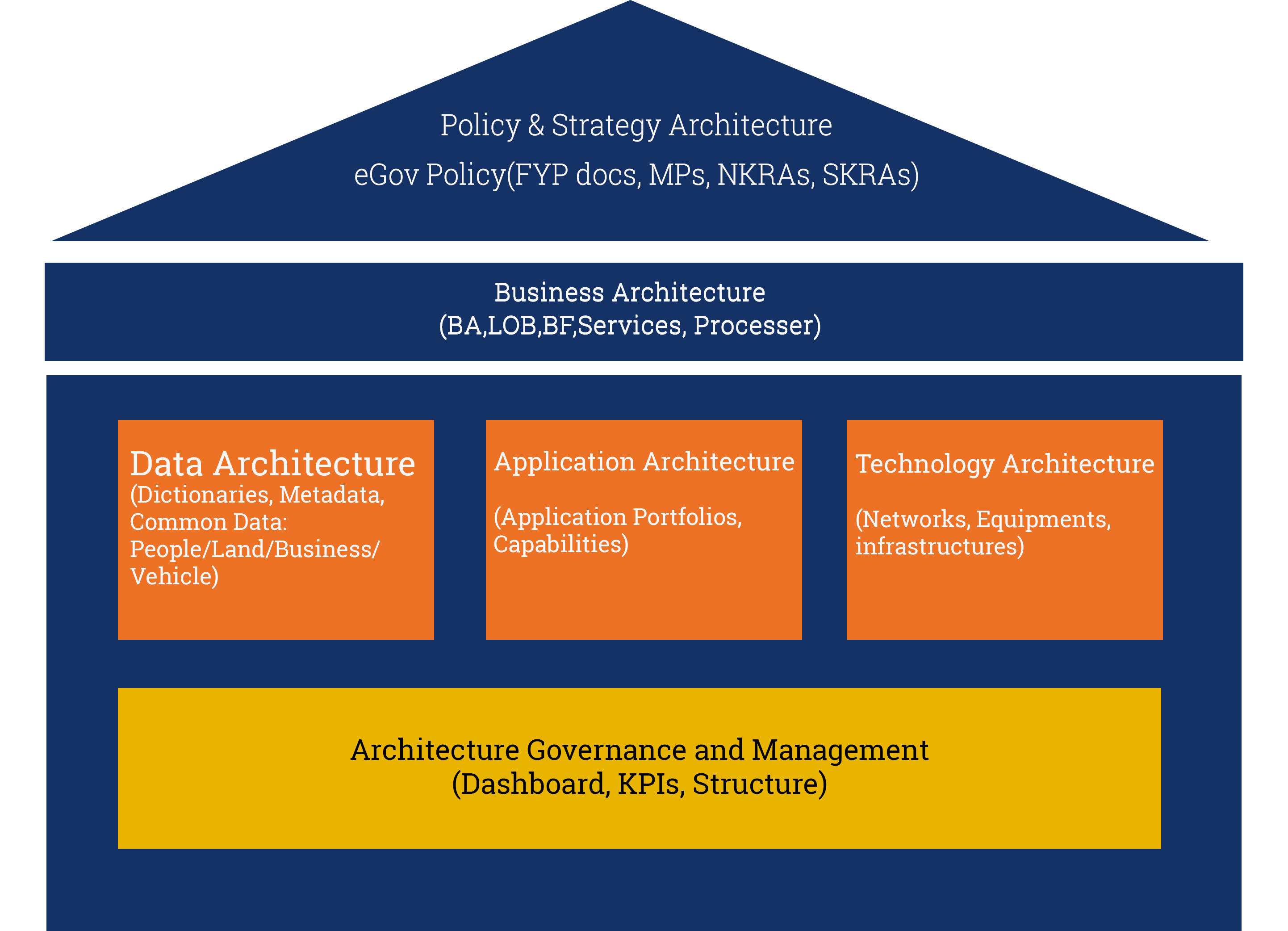
The Architecture
Business
Application
Technology
Data
Milestones
2017
Open Group Awards
Government Enterprise Architecture, e-GIF (eGovernment Interoperability Framework) of Royal Government of Bhutan, lead by the Department of Information Technology and Telecom, under Ministry of Information and Communications was selected for the Open Group 2017 Awards for Innovation and excellence in Enterprise Architecture.
March 2014
187 Public services automated
December 2012
Transition to Full Service
July 2012
e-GIF was born
ICT provides unprecedented opportunities to realize a nation's development vision and objectives. The implementation of e-Government can significantly enhance efficiency, accountability and transparency of Government functions and service delivery. Therefore, in keeping with the priorities of the government, there was need to put in place strategic plans, policies and ICT standards to support smooth implementation of e-Government. In order to address the above challenges, the RGoB has embarked on the development of an e-GIF portal using International standards and best practices which are catered towards Bhutan’s needs.
Help Us
Transition Our
Government!
Datahub SOP
1. API Development and Sharing of Data
The main purpose of this SoP is to guide the individual or agencies on how to share and consume data from the datahub in a secure way to protect data privacy of individuals and citizens as a whole.
Each organisation must follow its own procedures regarding information security and confidentiality before sharing with consuming agencies.
This SoP is not designed to supersede existing policies but to enhance them by facilitating cross-agency dialogue and consensus by providing a context for information sharing.
1.1 Procedure to Follow in Staging Environment by Data Consumer,Data Owner and DITT
A. Data Consumer Responsibility
If agencies want information from other agencies (data owner), they must write formally to the data owner by clearly specifying the resources and get approval from the data owner.
Without the approval, the datahub team will not be able to share the information even if the API is available in datahub.
This gives the data owner the authority to maintain confidentiality and privacy of the information before they give approval to access the requested information by consuming agencies on a case by case basis.
The data consumer has to share the approved letter from the data owner to DITT to initiate the development of API.
DITT will in turn follow up with the data owner to provide with sql query and database details for API development.
B. Data Owner Responsibility
The data owner must review each incoming request from the data consumer based on resources and decide to give approval or not based on classification of datas. If the data owner approves the request to access its information via datahub platform.
Data owners have to provide the following details to the DITT datahub team to initiate the API development.
SQL queries with few input parameters to test the query.
Create a mirror of live database (data can be jumbled up)
Create a user for data hub with required privileges (execute the query)
Share the database details such as database name and type, port, IP address, and user created in no 3 above along with password.
White listing of IP from your firewall is configured.
It is also the responsibility of the data owner to maintain the list of agencies approved for access to their mirror database. This will give clear information about who is accessing what data for what purpose.
C. DITT Responsibility
The DITT upon getting the query and database details, we will first execute the query in a local machine, if there is no issue, we will continue to develop the API. If there is an issue, we will contact the data owners to resolve the issue.
The API development will take a minimum of 5 working days and will be pushed to the staging environment on the 5th day, ready for testing by the agencies.
DITT will inform the both data consumer and owner about it and share the API credentials with the data consumer to start integrating their system.
Agencies can share the staging API credentials with their consultant during the development phase to integrate the system with datahub and test if required data is being pulled from the data sources.
The following information will be shared with data consumers from the staging environment by DITT.
Access Token code, only in for testing purposes.
Client secret
Consumer key
API endpoints/url
SDK files as necessary
The procedure on how to develop API is an internal document within the Team.
1.2 Procedure to be followed in production environment by data consumer, data owner and DITT.
A. Data Consumer Responsibility
The data consumer has to inform the Datahub team about their successful test completion in the staging environment and ask us to push the same API to the production environment.
B. Data Owner Responsibility
Data owners have to provide the following details to the DITT datahub team to push the API to the production environment.
Create user in live database,
Give required privileges to above user (execute the query)
Share the database details such as database name and type, port, IP address, and user created in no 3 above along with password.
White listing of IP from your firewall is configured.
It is also the responsibility of the data owner to maintain the list of agencies approved for access to their live database. This will give clear information about who is accessing what data for what purpose.
C. DITT Responsibility
The DITT upon getting the query and database details of the live server from the data consumer, we will push the API to the production environment within 2 working days.
DITT will inform the both data consumers about it and ask the data consumer to come and sign NDA in person to DITT.
DITT will share the API credentials only with the person who signed the NDA.
Agencies can’t share the production API credentials with their consultant. It has to be configured by IT of the respective agencies.
If there is anonymous access to data using the API credentials leaked from this application, the person who signed NDA will be held accountable.
The following information will be shared with data consumers from the production environment ( following information will be shared via email etc.. person signing NDA has to take in flash drive or in secure way)
Client secret
Consumer key
API endpoints/url
SDK files as necessary
The focal person who signed up to this NDA is legally responsible for ensuring the safety and confidentiality of the production environment of the data hub API that is shared.
It has to be properly handed over to the next officer in charge, in case the focal person leaves for long term studies or on transfer to another organization.
1.3 Seeking Consent
If the agencies/data consumer has to share productionAPI information with their vendor for integration issues etc, then the consent has to be sought from DITT and the focal person from the vendor has to also sign NDA before sharing the API credential to ensure that he didn’t disclose or misuse the information.
The focal person who signed the NDA will be held accountable as per the law, if there is any compromise to the data, if they share the API credentials openly or they tried to access unauthorised database. The signing of NDA is to secure and protect the data from anonymous access with valid keys.
A. Important Note to Data Owner.
It is utmost important for the data owner to keep their database up and running. Also, ensure the user created for datahub is not changed or revoked.
If data owners are making changes to their database, the data owner has to inform the Datahub team, so that changes are made at same time without downtime.
The DITT datahub platform has an analytic tool that will show the number of downtimes for the database, which resulted in downtime of API and agencies not able to consume the data.
This will impact the data owner IT in their performance rating from the Department.
1.4 Responsibilities for API Development
A. API Development
To develop a new API, the data consumer, the data owner and DITT has to follow the following roles and responsibilities described below.
Stakeholders
Process
Data Owner
Data owner shall maintain documentation of API details with resources and data exposed. To check the API details using the below link: https://staging-datahub-apim.dit.gov.bt/store. It contains available resources within the API
The data owner has to inform the datahub team, if data owner want to make any changes to their database such as ( change in database name, ip, fields in table, change in query, creation and deletion of existing user provided to datahub, access privilege to the user provided to datahub).
Data owners shall authorise data consumers to use APIs and resources within the API.
In case consumers need more data or resources within the existing API, Then data consumer has to formally request the data owner for access to additional resources. The data owner will choose to expose a new set of datas as either a new API or modify the existing API.
Data owners has to officially inform DITT with following information:
SQL Queries and data source informations (Database type, schema name, Server IP, and user credentials to access database )
Security concerns : The classification of the data/resources as either public, internal and sensitive information, so that API can be developed accordingly.
The data consumer shall get prior approval from data owners to consume their data through API from data hub.
The data consumer has to spell out clearly which data field they want to access from the data owner when seeking approval.
To initiate the API consuming process, Consumers shall write officially to DITT to consume API from the datahub platform with the following information.
Client Application Details (Language, Web or mobile, whether it is hosted in the Govt Data Center or not)
List of APIs necessary if known/ or list of data necessary
Expected number of API calls (TPS)
Is your application accessible by Citizens?
If access is required by citizens, then it has to integrate with the single sign on (SSO) platform, in this case the agencies have to provide DITT with redirect URLs of the application (login and logout).
Authorization letters from data owners
In case API is not available in the API store or the required data are not available, then data consumers have to seek permission to consume data and request modification of existing API or to develop a new API with required data from the data owner.
List of operations with input and output parameters
DITT
Interim Procedure
Verify the SQL query with Input and output parameters with data owners and consumers.
Develop and test API in 5 working days and publish in staging environment for data consumers to initiate integration
If the API already exists, but requires additional data from the same API, then DITT will modify the existing API at resource level within 5 working days and publish in a staging environment for data consumers to initiate integration.
Long Term
DITT will provide a Git location to store the API source codes and development guidelines.
Once the development is completed, test the APIs in the testing environment.
Commit the source codes to the Git repository provided by DITT.
Inform the DITT team to configure the CI/CD (Jenkins) and build the project using Jenkins and deploy to the datahub staging environment.
Agencies will test the API in staging environment
Once the test in staging is complete, agencies have to inform DITT to promote the API to production with details of live connection to their database.
New API development will take a minimum of 5 working days upto 22 working days depending on the complexity of the API necessary
DITT will not accept changes to modify the API that are tested and published in the production environment. Modification will be done with versioning of API every after 6 months.
B. Subscribing to Exposed APIs
To subscribe to exposed APIs, the data consumer has to get an approval letter from the data owner and send a request to DITT along with the approved letter.
The DITT will create a user for the agencies (data consumer) and with that user credential.
DITT will create an application in the API manager and provide access to the API. The DITT will provide data consumers or their consultants(developers) with the consumer secret, consumer key, access token and API endpoint url along with the SDK files ( jar files) to integrate the systems via data hub platform from staging environment only.
The production environment API details will be shared with the focal person of the data consumer in person after signing of this document and will not be shared with consultant or vendor in any case.
C. Moving APIs to Production
To move the API to the production stage, it has to first be tested in the local machine with the given input and output parameters by the data consumer. Upon successful test with given parameters, the same API is then pushed to staging production and DITT will share the consumer secret, consumer key, access token and API endpoint url to test and integrate their systems to the data hub platform.
Once it is fully tested in the staging server, then the agencies have to inform DITT to push the same API to the production environment.
Once the API is pushed to production, DITT will share the configuration information like consumer key, consumer secret, access token and API endpoint with the focal person and agencies have to configure without engaging outside consultants.
This is to ensure security and unauthorised access of APIs using the above credentials.
In the event of non compliance with this Agreement and the sharing of details of API to vendors or any outside entities, data consumers shall be liable for any data privacy loss and access tokens shall be revoked immediately.
The data hub analytics shall monitor the traffic generated from each application for every API published. Unexpected traffic will be apparent and DITT shall notify the data consumer and will monitor the issue and if unauthorized access is suspected, DITT shall promptly Revoke authorizations to suspected applications and other applications under the same network if necessary.
This will remain in effect until all necessary remedial actions are taken promptly and demonstrated to the DITT.
1.6 NON DISCLOSURE AGREEMENT
This agreement is entered into this 20 day of April, 2020 between ...................... (hereinafter "Recipient"), with offices at ...................., and Dawa Tshering, with offices at DITT (hereinafter "Disclosure").
WHEREAS Disclosure possesses certain ideas and information relating to API of production that is confidential and proprietary to the Disclosure (hereinafter "Confidential Information"); and WHEREAS the Recipient is willing to receive disclosure of the Confidential Information pursuant to the terms of this agreement for the purpose of integrating the system to data hub platform and consume the data; NOW THEREFORE, in consideration of the mutual undertakings of the Disclosure and the Recipient under this agreement, the parties agree to the below terms as follows:
Disclosure.The Disclosure agrees to disclose, and Receiver agrees to receive the Confidential Information.
Confidential
No Use.The Recipient agrees not to share the Confidential Information in any way with the consultant/vendor or manufacture or test any product embodying Confidential Information, except for the purpose authorized by the Disclosure.
No Disclosure.The Recipient agrees to use its best efforts to prevent and protect the API Information, or any part thereof, from disclosure to any person other than the Recipient's employees that have a need for disclosure in connection with the Recipient's authorized use of the production Information of API.
Protection of Secrecy. The Recipient agrees to take all steps reasonably necessary to protect the secrecy of the Confidential Information and to prevent the Confidential Information from falling into the possession of unauthorized persons.
Limits on Confidential Information.Confidential Information shall not be deemed proprietary, and the Recipient shall have no obligation with respect to such information where the information:
Was known to the Recipient prior to receiving any of the Confidential Information from the Disclosure;
Has become publicly known through no wrongful act of the Recipient;
Was received by the Recipient without breach of this agreement from a third party without restriction as to the use and disclosure of the information;
Was independently developed by the Recipient without use of the Confidential Information; or
Was ordered to be publicly released by the requirement of a government agency.
Ownership of Confidential Information.The Recipient agrees that all Confidential Information shall remain the property of Disclosure and the Discloser may use such Confidential Information for any purpose without obligation to Recipient. Nothing contained herein shall be construed as granting or implying to the Recipient any transfer of rights, any patents, or any other intellectual property pertaining to the API Information.
Term and Termination.The obligations of this agreement shall be continuing until the Confidential Information disclosed to the Recipient is no longer confidential. In the event of non compliance with this NDA and the sharing of details of API to vendors or any outside entities, data consumer shall be liable for any data privacy loss and access tokens shall be revoked immediately.
Survival of Rights and Obligations.This agreement shall be binding upon, inure to the benefit of, and be enforceable by (a) the Discloser, its successors and assignees; and (b) the Recipient, its successors and assignees.
Change of Focal Officials: If the recipient is no longer taking in-charge of this API, this NDA has to be re-signed with the new focal of the API. It is the responsibility of the Recipient to inform the Disclosure in writing, officially, of the change in focal officials.
IN WITNESS WHEREOF, the parties have executed this agreement effective as of the date first written above.
Discloser (Name of the Discloser)
Signed ..........................................
Print Name :.....................................
Title:...........................................
Date :...........................................
Recipient (Name of the Recipient)
Signed ...........................................
Print Name :......................................
Title:............................................
Date :............................................
.
eHealth EA Blueprint
The Nation with the Best Health
The Royal Government of Bhutan has accorded priority to tapping the potential of ICT in various sectors. Guided by the vision “the nation with the best health”, the health sector has emphasized the importance of using ICT-enabled solutions to improve the delivery of quality care to the people of Bhutan.
The ICD is originally designed as a health care classification system, providing a system of diagnostic codes for classifying diseases, including nuanced classifications of a wide variety of signs, symptoms, abnormal findings, complaints, social circumstances,and external causes of injury or disease.
The clause 5.4 of the National Health Policy of Bhutan, 2011 states that “The Royal Government of Bhutan shall provide 100% nationwide access to a health care professional through technology-enabled solutions.
Furthermore, Clause 7.2 of National Health Policy 2011 states that “Digitised Health record and information system shall be instituted in all the health facilities for faster and effective health information generation to support decision making.”
The ICT Division was established in the ministry to spearhead, review and manage all the ICT/eHealth activities and guiding the programmes in investing in the area in 2017.
This was followed by the development of the National eHealth Strategy and Work Plan which in 2017 with support from ADB and WHO which served as a lighthouse to ICT initiatives in the ministry.
This also established the National eHealth Steering Committee which served as the governing body for any ICT activities for the ministry and eHealth Technical Working Group was established to carry out review or carry out the ICT activities.
National eHealth Enterprise Architecture Blueprint
Bhutan has successfully come out with an National eHealth Enterprise Architecture Blueprint in December 2020 to ensure all the systems can exchange data seamlessly.
Bhutan's approach to implementing HIS is to have a standard HIS system across all the health facilities in the country and also get data from other stakeholders which has been successfully tested in the COVID19 system implementation.
Another advantage Bhutan has is that the country has information of any individual residing in Bhutan be it Bhutanese citizen or foreigner.
Therefore, it is only imperative for Bhutan to adopt such a system by any means which shall be expensive in the beginning but shall soon payoff in terms of efficiency and huge health care expenditure savings.
If Bhutan can roll out this project successfully, Bhutan will be one among few countries in the world to roll out standardized integrated healthcare IT solutions across the nation that include non-allopathic facilities (Traditional Medicine Hospital/Clinics).
This shall help Bhutan in achieving the goal of Universal Health Coverage (UHC) which every nation in the world is aspiring.
The details document can be found in the link shared below:
The International Classification of Diseases (ICD)
The International Classification of Diseases (ICD) is a globally used diagnostic tool for epidemiology, health management and clinical purposes. The ICD is maintained by the World Health Organization (WHO), which is the directing and coordinating authority for health within the United Nations System.
The ICD is originally designed as a health care classification system, providing a system of diagnostic codes for classifying diseases, including nuanced classifications of a wide variety of signs, symptoms, abnormal findings, complaints, social circumstances,and external causes of injury or disease.
This system is designed to map health conditions to corresponding generic categories together with specific variations, assigning for these a designated code, up to six characters long. Thus, major categories are designed to include a set of similar diseases.
The ICD-11 Revision
The ICD-11 is the eleventh revision of the ICD. It replaces the ICD-10 as the global standard for coding health information and causes of death. The ICD-11 is developed and regularly updated by the World Health Organization (WHO).
Its development spanned over a decade of work, involving over 300 specialists from 55 countries divided into 30 work groups, with an additional 10,000 proposals from people all over the world. The stable version of the ICD-11 was released on 18 June 2018, and officially endorsed by all WHO members during the 72nd World Health Assembly on 25 May 2019.
The ICD-11 is a large ontology consisting of more than 80000 defined entities, also called classes or nodes. An entity can be anything that is relevant to health care.
It usually represents a disease or a pathogen, but it can also be an isolated symptom or (developmental) anomaly of the body. There are also classes for reasons for contact with health services, social circumstances of the patient, and external causes of injury or death.
The collection of all ICD-11 entities is called the Foundation Component.From this common core, various subsets can be derived; for example, the ICD-O is a derivative classification optimized for use in oncology.
The ICD-11 MMS Foundation
The primary derivative of the Foundation is called the ICD-11 MMS, and it is this system that is commonly referred to as simply "the ICD-11". MMS stands for Mortality and Morbidity Statistics.Both the Foundation Component and the ICD-11 MMS can be viewed online on the WHO's website.
The ICD-11 further includes extension codes that cover medicaments as defined in International nonproprietary names, chemicals, infectious agents, histopathology, severity, mechanisms of injury, or anatomy.
ICD-11 ontological structure provides advanced user guidance and assistance in code combinations.The technology can be accessed by any software via API or by humans using the coding tool.Print versions will be made available on demand.
The ICD-11 will officially come into effect on 1 January 2022, at which time member nations may begin reporting morbidity and mortality statistics using the ICD-11 nosology.The WHO has acknowledged that "not many countries are likely to adopt that quickly", i.e. begin using the ICD-11 by the time of its launch.
Bhutan as one of the active member countries of WHO has also adopted ICD-11 by defaults and has started implementing it starting from 2020.As the nation is in the process of digitizing healthcare services using ehealth and mhealth solutions, the adoption of this health standard could not be more timely.
Since the Ministry of Health has adopted this standard, any office, agencies or system planning to use such disease either built, collect or access disease data are mandated to use these standard coding.
More details are available at the WHO ICD-11 (https://icd.who.int/en) website or else please contact officials of the Health Information Management System Team under the MoH.
eGov Governance Team
Jigme Tenzing
Director
Lobzang Jamtsho
Business Architect
Contact Us
Your feedback is important.
Business Architecture
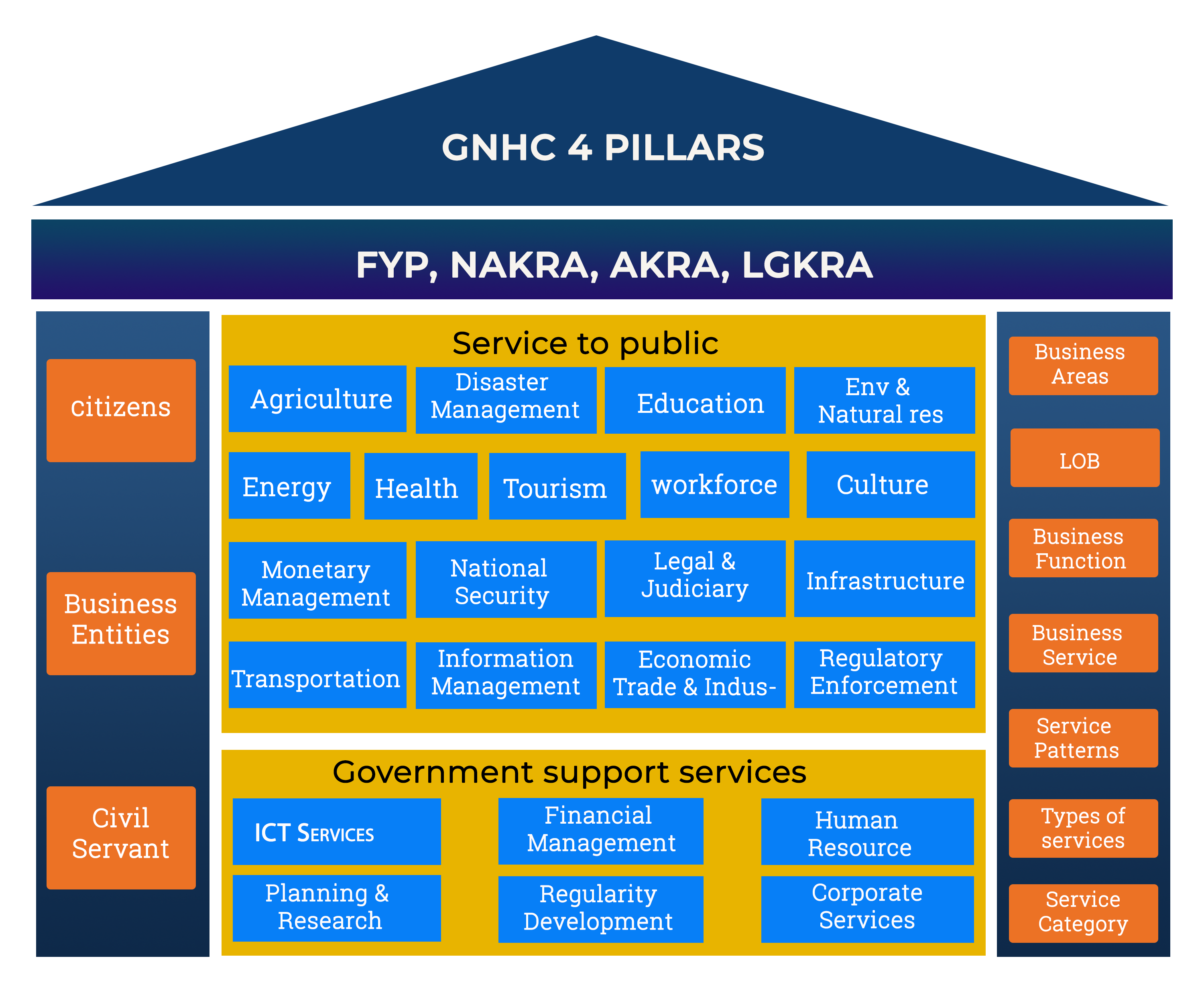
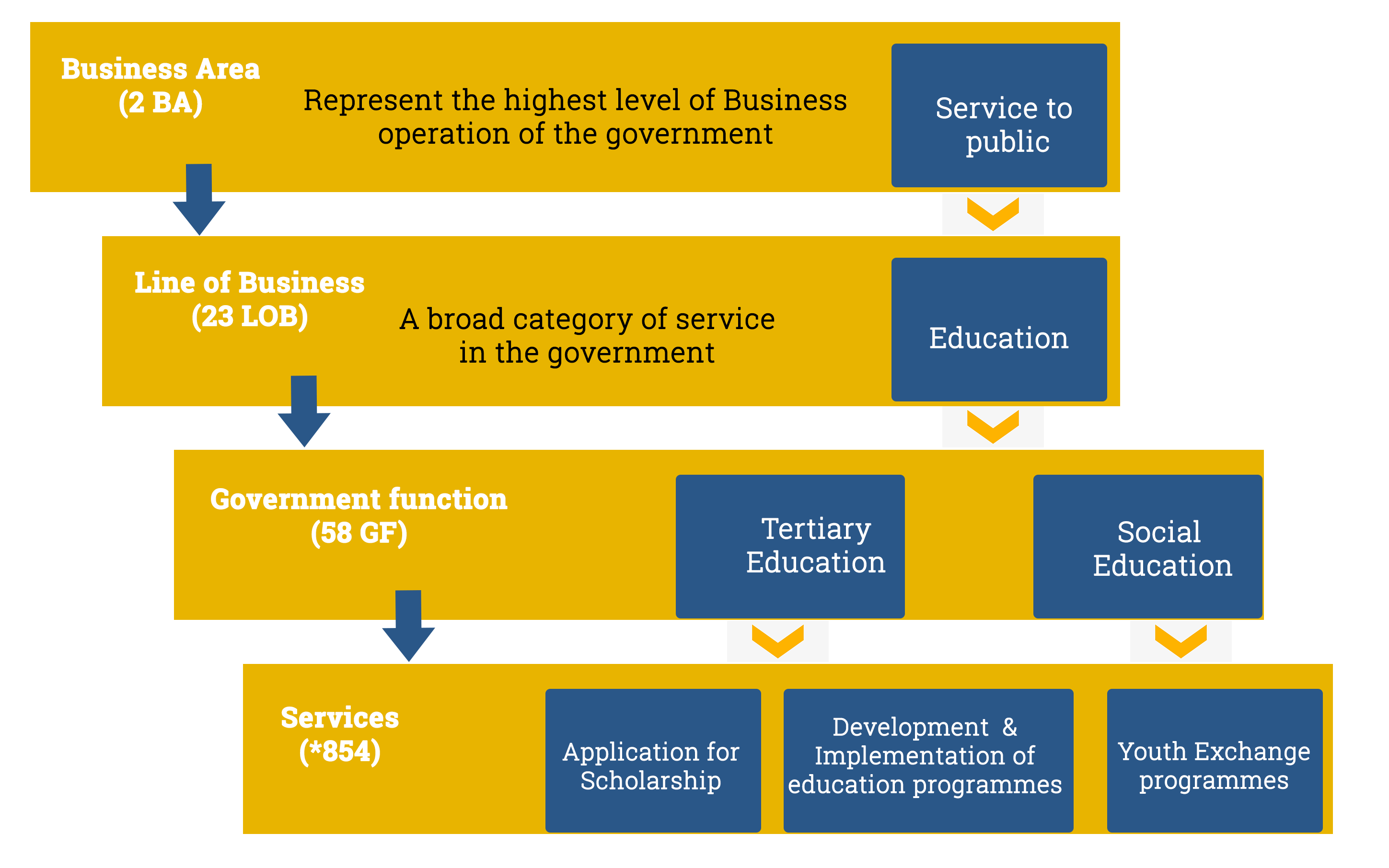
The Business Architecture defines and provides detailed description of the business areas, government-wide lines of business, their associated government functions and services performed by the RGoB. It ensures strategic alignment of business functions and services to the objectives of the RGoB, and promotes collaboration amongst RGoB agencies in delivering government functions around common business areas. The Objective of this reference model is to align services and functions performed by different agencies within the RGoB with the business objectives of the RGoB.
Business Architecture Components
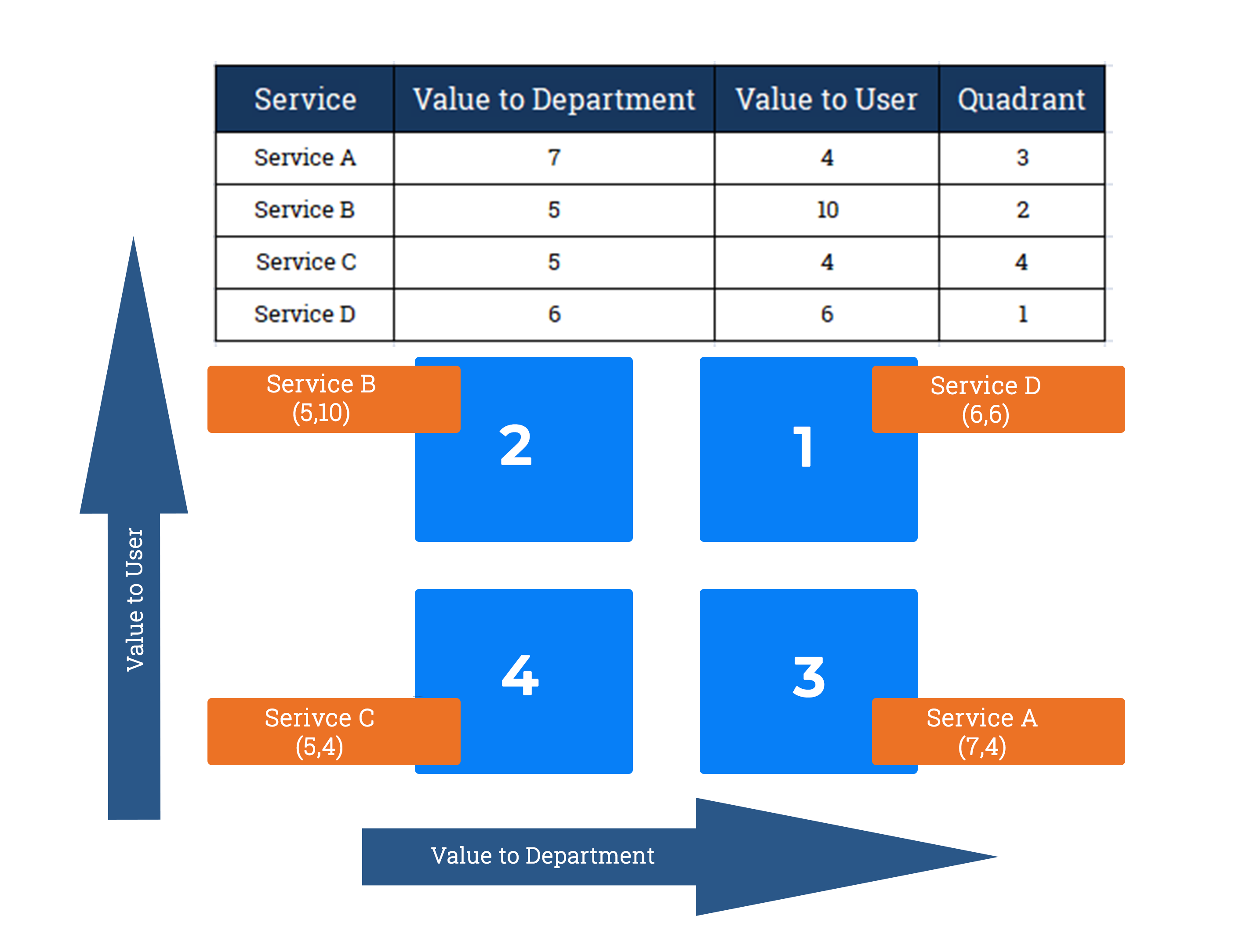
BRM provides a complete government-wide perspective of Lines of Business, the associated Government Functions, and the services delivered by the RGoB. The BRM does not cover National Defence, the National Council and the National Assembly, Office of the Gyelpoi Zimpoen and HM secretariat. The following is an example of a government-wide line of business, its associated Government Functions and Services. The line of business falls under the Services to Public vertical business area. Services are first categorized according to the service categorization matrix. As shown, the each quadrant indicates the value of a service in two dimensions: value to department, and value to user.
Service Rationalization
The rationalization agenda is primarily established to move away from agency centric view of the services and make them citizen-centric by taking a whole-of-government perspective. This means looking at each and every service from a point of view that considers the actual use of the service. The following aspects can be considered during this activity. Elimination of duplicates: If the same or similar service is provided by more than one agency, consider creating only one service and eliminate the redundant ones. This might mean only one agency providing the service, or two agencies co-operating to provide a single service for the user.Remove pre-requisite services: There are services that are required as a pre-requisite to other services. For example, a birth certificate may be needed to access multiple other services. A birth-certificate otherwise serves no other useful purpose. Therefore, this service can be included as an automated verification check of birth records for the dependent services; there is no need for a standalone service to issue birth certificate. This is possibly true of many other registration certificates. we should consider if they really need to be issued as certificates, or is it enough just to record the fact of registration and use this record for granting access to dependent services. Eliminate duplication of common services: If a service can be replaced by a common service, consider eliminating it and moving to the common service. The requirements of each case needs to be elaborated. There has to be certain give and take to move towards the common service because a common service may not satisfy 100% of the requirements of the existing service; but this is to be expected so architects need to persuade the stakeholders of the benefits of using the common service. Refer to section 4 for suggested list of common services.
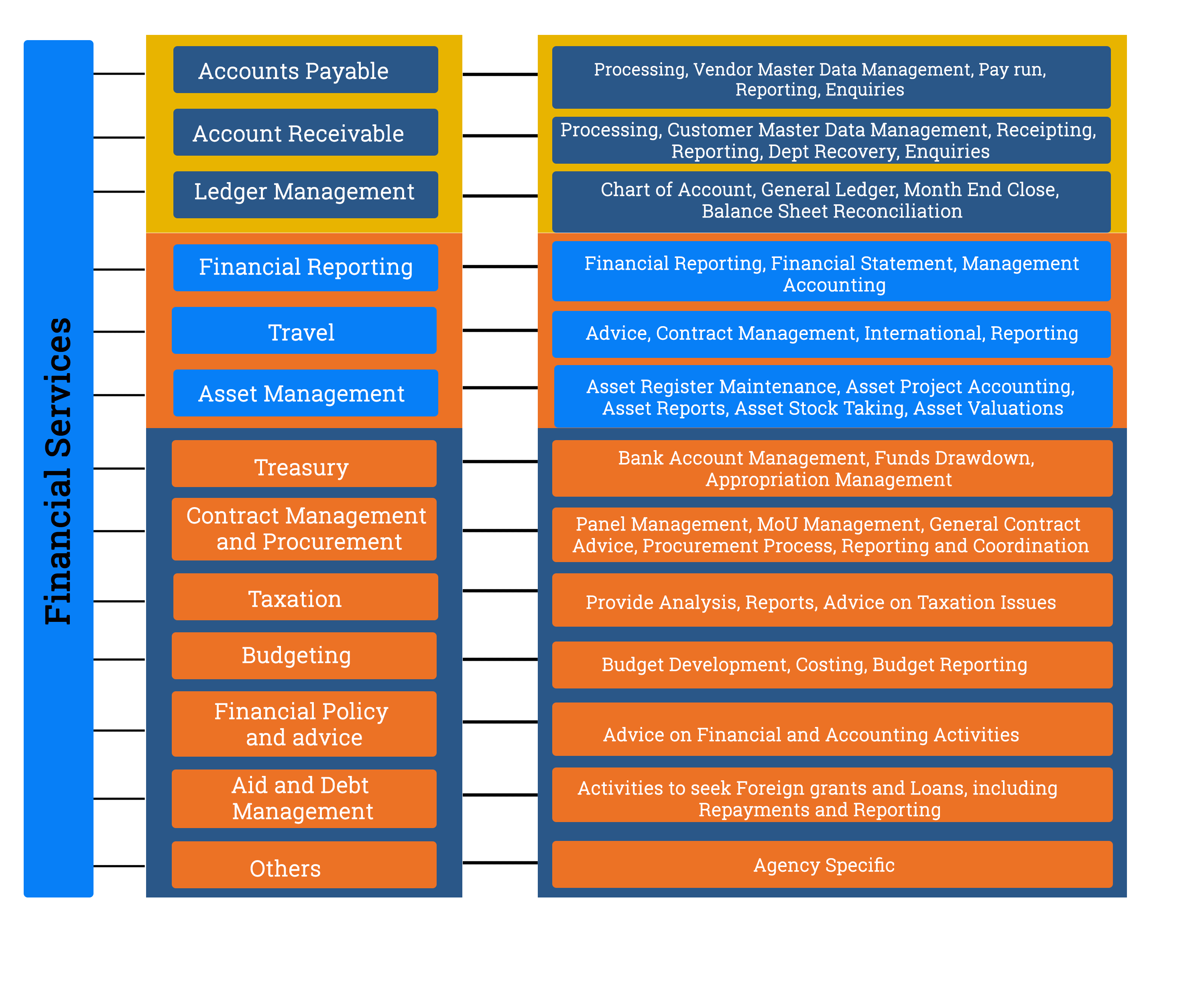
Line of Services
These services belong to the Line of Business(LOB) financial management[5].
The above Exhibit demonstrates the Services belonging to Line of Service "FINANCIAL MANAGEMENT"
Testing the image path
The Objective of Enterprise security architecture is to provide conceptual design of security infrastructure, related security mechanism and security policies and procedures. The architecture links components of security infrastructure as a unified unit. The goal of this cohesive unit is to protect information. The enterprise security architecture must ensure Confidentiality, Integrity and Availability throughout the enterprise and align with organization's core goals and objectives.
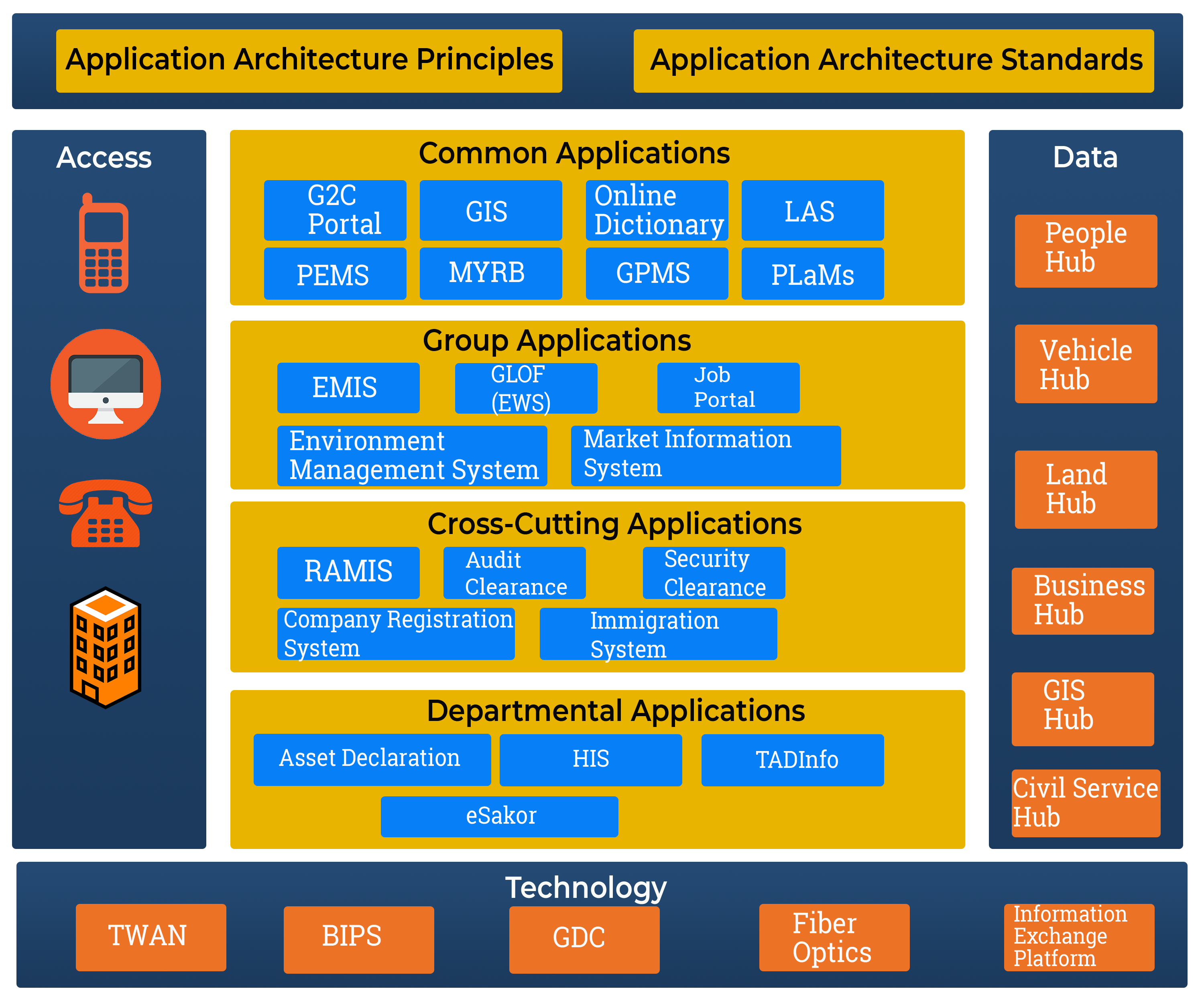
Application Architecture
Application Architecture defines the detailed description of the application systems used within RGOB. These application systems are needed to manage the data and support the line of businesses, government functions and services. It also documents a list of reusable application components of these application systems. The objectives of this reference model are to facilitate interoperability between application systems, identify reusable application components and facilitate application maintenance.
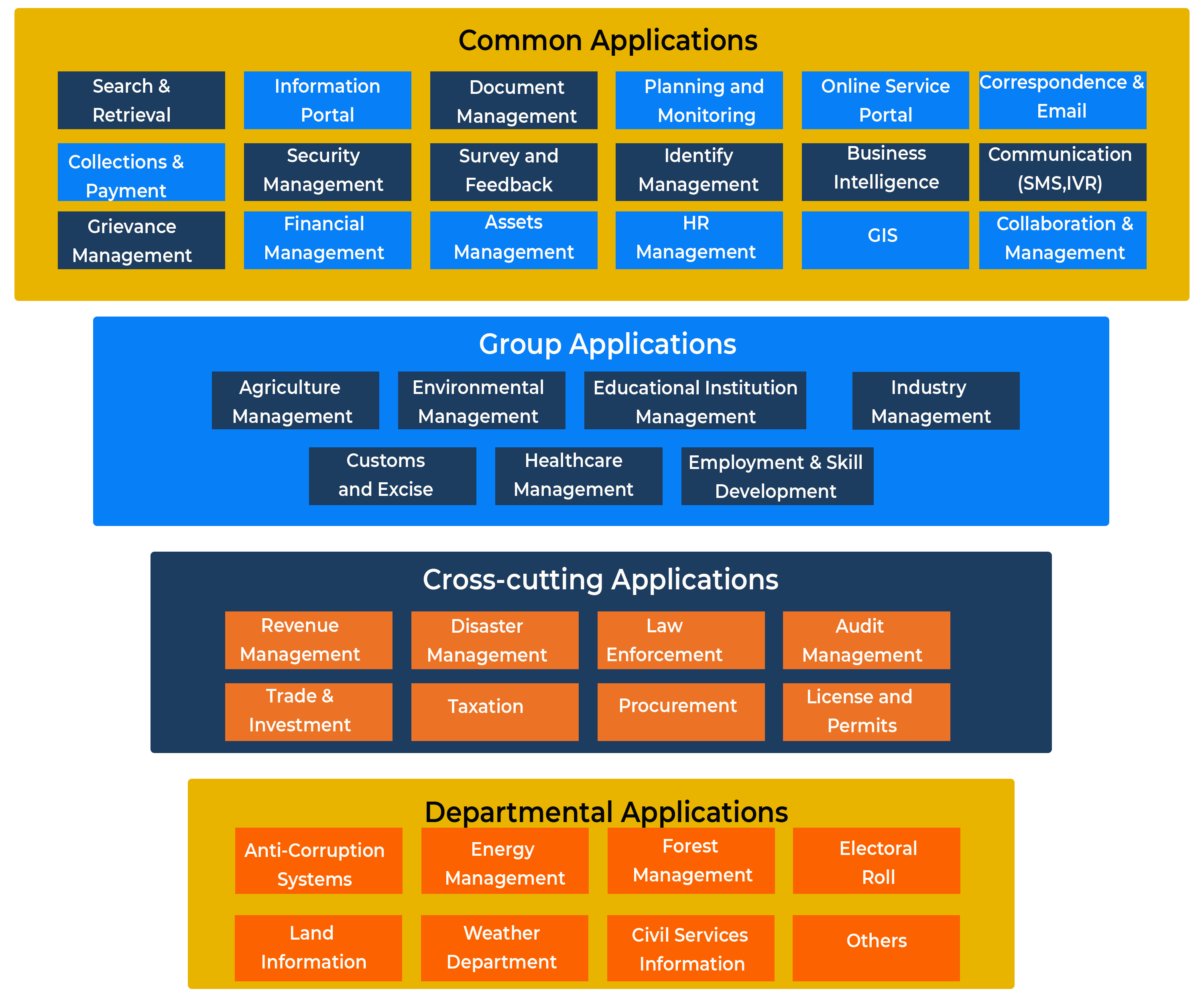
Categorisation of Application System
COMMON APPLICATIONS: These applications are common government-wide. These applications allow for the greatest economies of scale, usually comprise of all horizontal functions that have highest potential for sharing and commonalities. A representative list of possible common applications is given below. To qualify as a common application, the process supported by the application has to be common across WoG: for example, requesting and granting of leave. Secondly, the process has to be self-contained within each department. GROUP APPLICATIONS:These applications are applicable within the confines of a cluster. A cluster comprises of a group of ministry / departments that provide services in a single domain (e.g. health, transportation, education, social welfare, agriculture), and therefore bring in some scope of shared services and common assets within the cluster.DEPARTMENTAL APPLICATIONS:These applications belong within the confines of a single ministry / department. These services are self- sufficient within the agency and require no interaction or exchange with any other agency.CROSS-CUTTING APPLICATIONS:These are functions initiated by a lead agency, but require the involvement of multiple other agencies as stakeholders to perform specific, assigned tasks and activities within the service, contributing to successful completion. These multiple stakeholders participate in the service delivery in an orchestrated manner (i.e. they are subject to rules and sequencing). Some examples of this type of application are procurement, revenue management, disaster management etc.
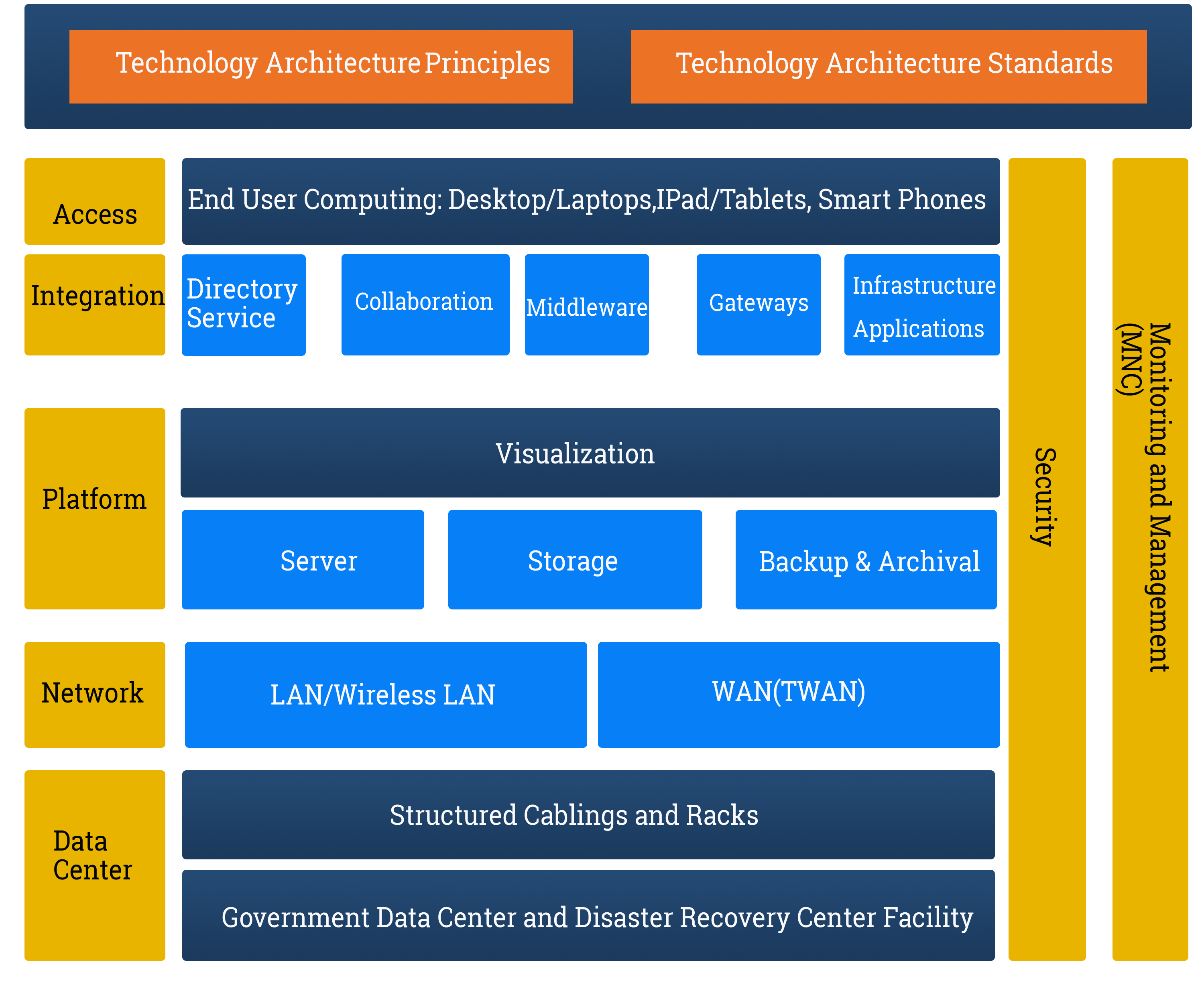
Technology Architecture
The Technology Architecture aims to support the E-GIF vision of delivering effective, automated and connected services of the highest standards and quality with a Whole of Government perspective. The intention is to provide a long-term view with a focus on the future technological needs. The vision sets the foundation for strategic technology planning, to provide flexible, efficient, common ICT solutions supporting citizen centric services, which enables RGoB to successfully achieve its goals and objectives and contribute towards achieving Gross National Happiness
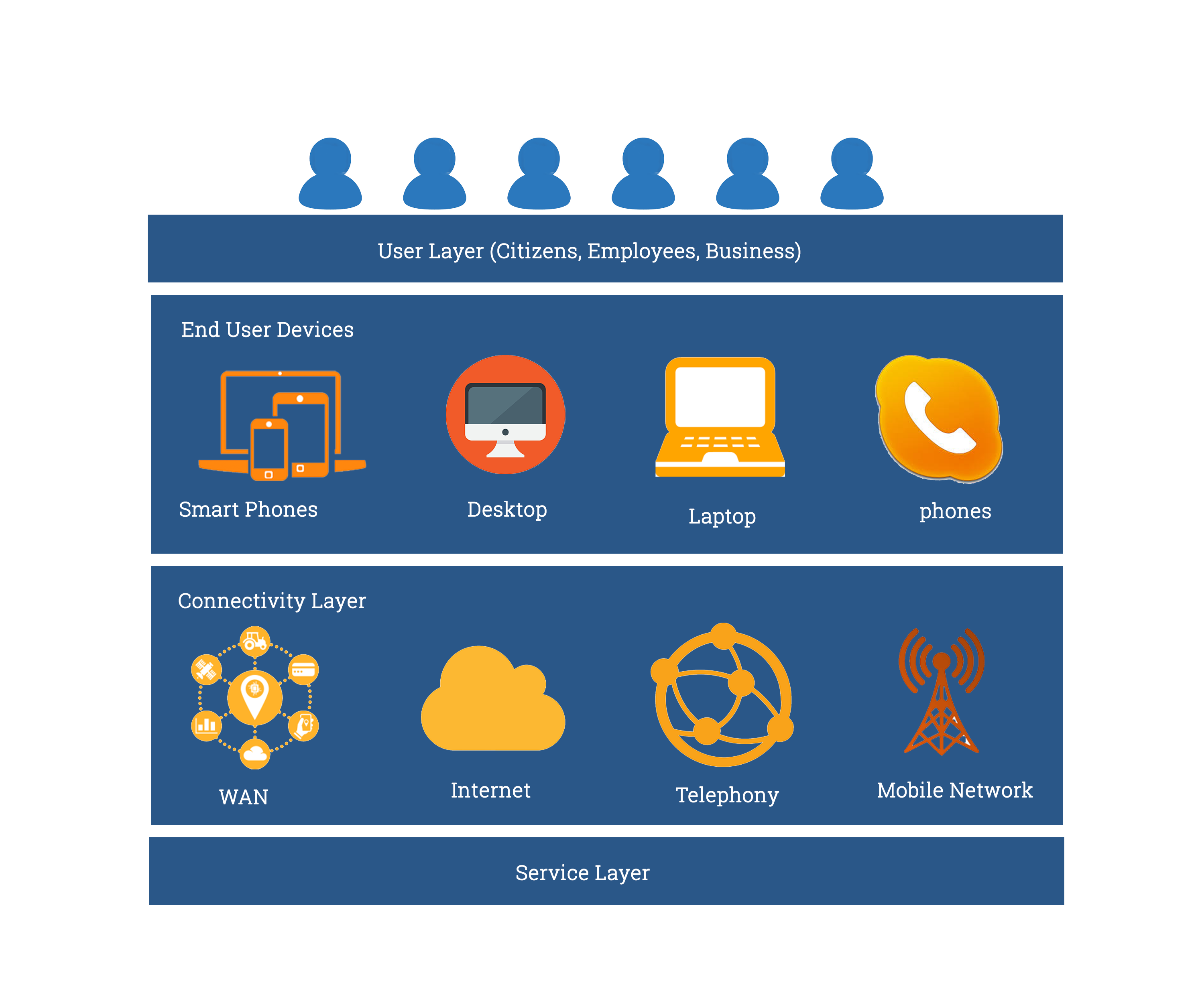
Access Domain
The access domain is described by end user access architecture. It has four layers namely- User, device, connectivity and service layers. Typically, user layer describes the types of users accessing government services, which are broadly divided in 3 types as 1· Citizens 2· Government Employees 3· Businesses. In order to achieve real ubiquitous service access, the user should be able to access the services at any point of time, from anywhere and any device such as PDAs/tablets, laptop/desktops, Smart Phones, Service Kiosks, etc. Hence, it is very important to provide the last mile connectivity infrastructure as mentioned in the connectivity layer of the exhibit.
Integration Domain
The integration domain describes building blocks used for interaction between various system environments for seamless delivery of service. It also covers services, which are used across government agencies and delivered by common applications. Middleware in the context of distributed applications is software that provides services to enable the various components of a distributed system to communicate and manage data, acting as â??glueâ?? to connect all systems together. Middleware supports and simplifies complex distributed applications. It includes web servers, application servers, messaging and similar tools.
Server Domain
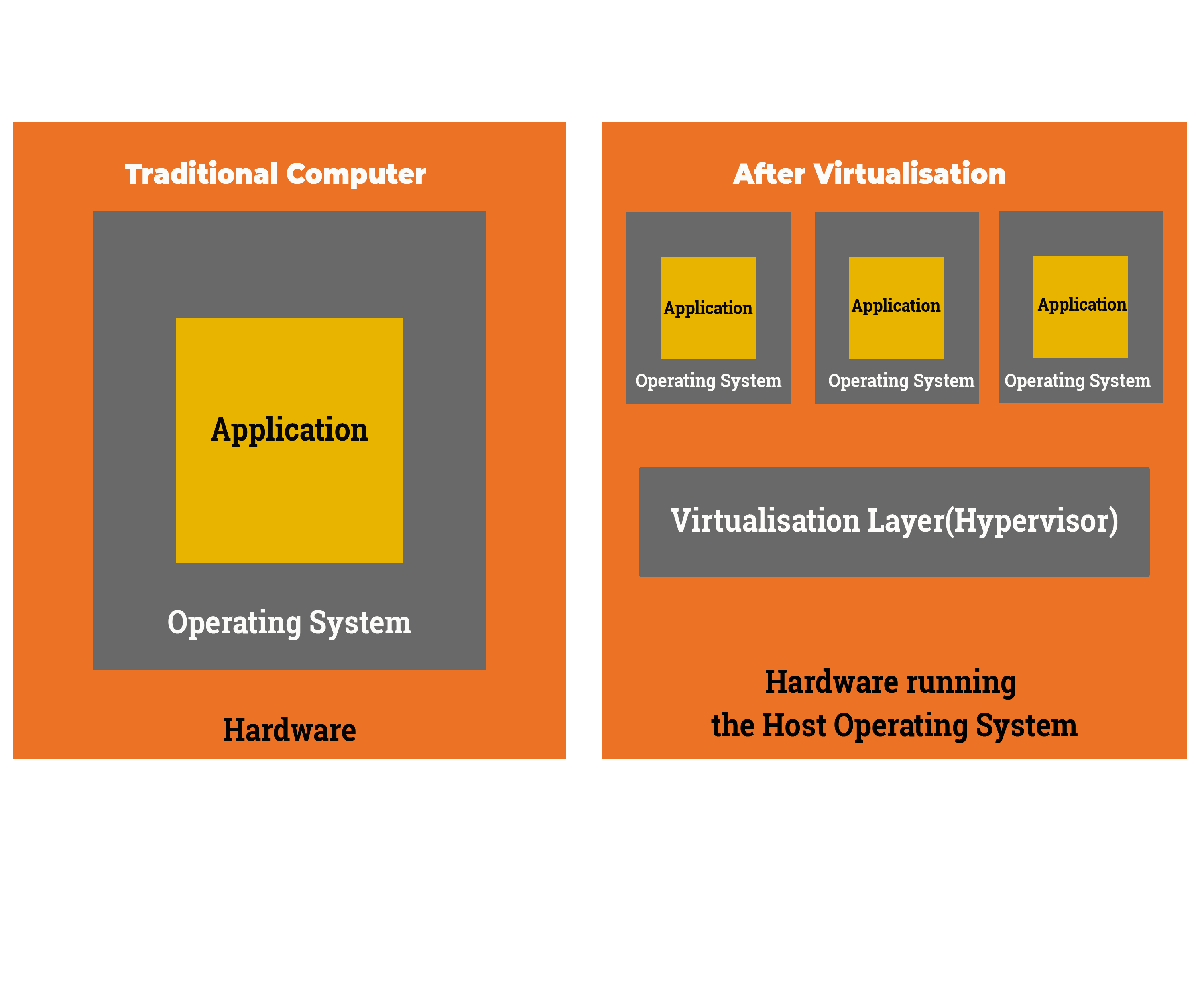
The current server infrastructure is distributed and maintained by respective departments of RGoB. All the applications run on separate physical servers leading to underutilization of resources. Hence, there is a need of consolidation and virtualization of servers and storage for cost-effective, efficient, scalable and available architecture. RGoB has a vision to move towards cloud. Virtualization is the preliminary step towards that. Server architecture is an important part of platform domain. It normally has 3 layers â?? Web, Application and DB which cater to different requirements. The proposed server architecture will enable government to migrate from traditional environment to modern virtualized environment.
Storage Domain
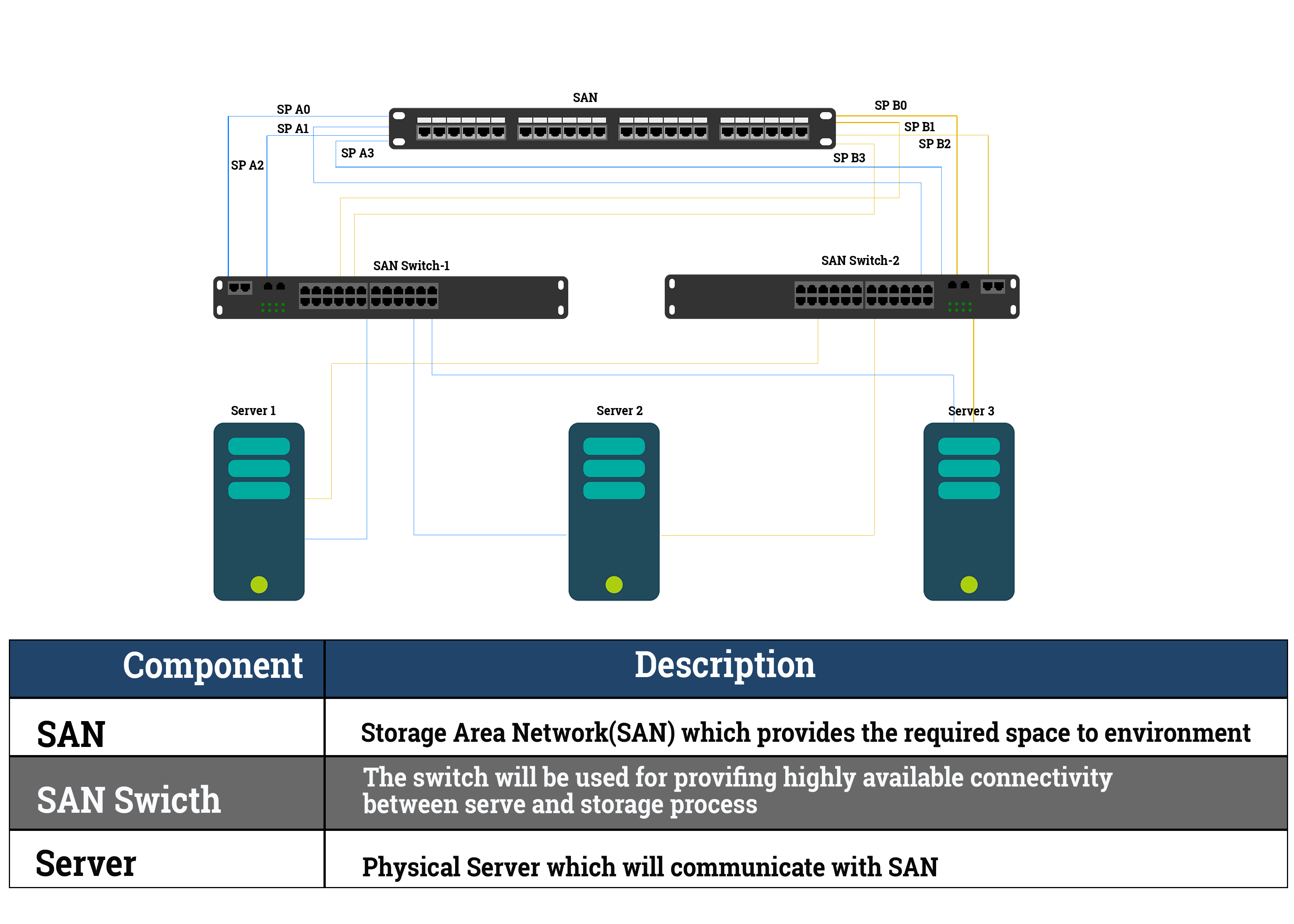
Information has become our most valuable asset. The challenge lies in making information available and keep it secured. To achieve this, storage becomes important part of IT architecture. As of now, different departments of RGoB are maintaining their own setup of storage infrastructure. As we move towards architecture supporting connected government, inter-operable systems and boundary less information flow, the islands of storages have to be consolidated into a centralized virtual pool of resources. This will help in achieving centralized management, cost effectiveness, faster provisioning and lesser time to rollout new services.
Network Domain
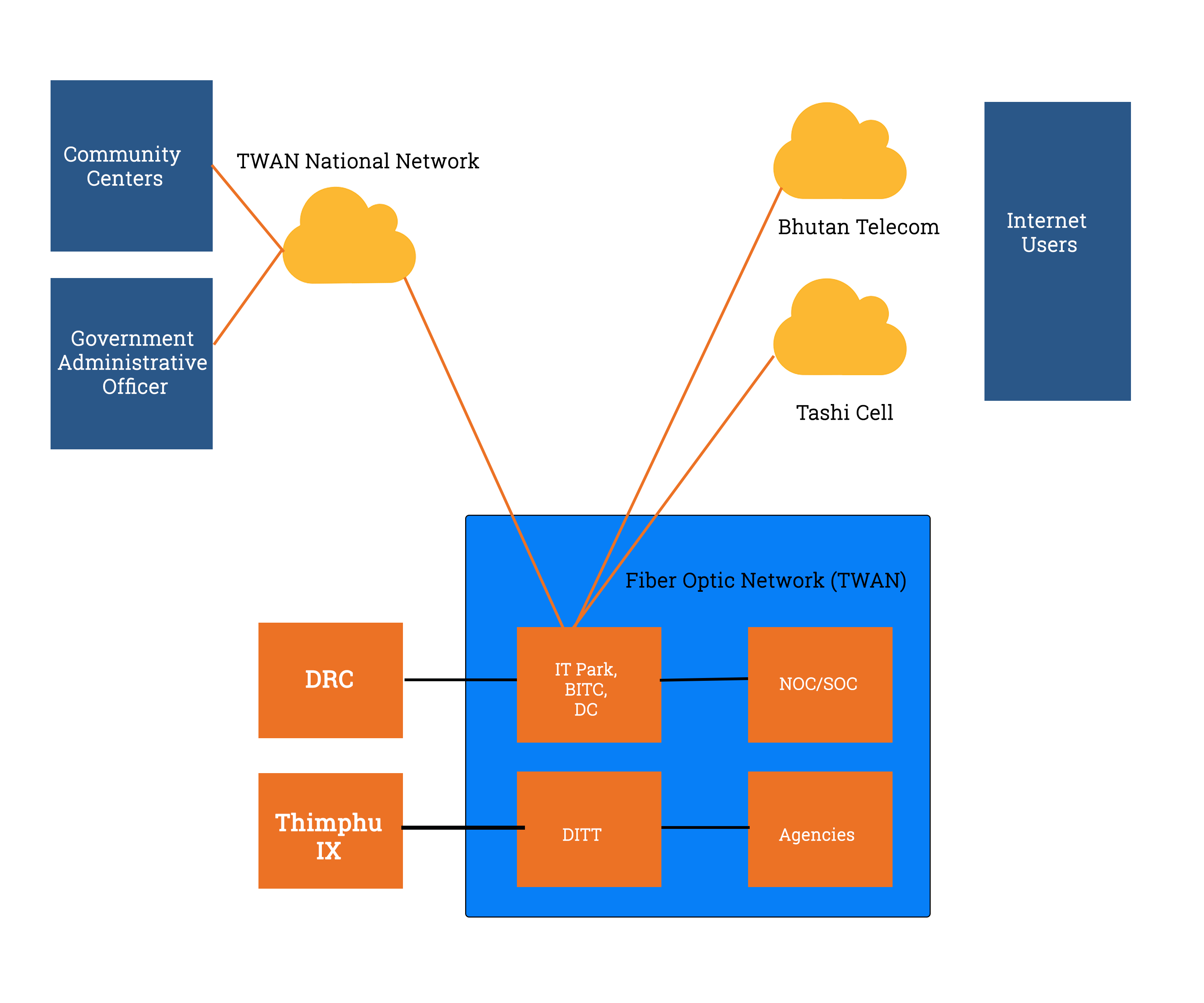
The enterprise network is another important building block of technology architecture. It depicts the connectivity infrastructure both at Data Center as well as at WAN level. TWAN is a government network, which provides a secure and dedicated environment for the RGoB to conduct its business functions. It is a high-speed network connecting all ten ministries, the Prime Minister's office and other government agencies in Thimphu. The Dzongkhag administration offices are also connected to this network. This connection is further taken to Gewogs and Dungkhags as well as Community Centres (CCs). RGoB should leverage TWAN to provide government services to agencies as well as to the public through the CCs.
Data Center Domain
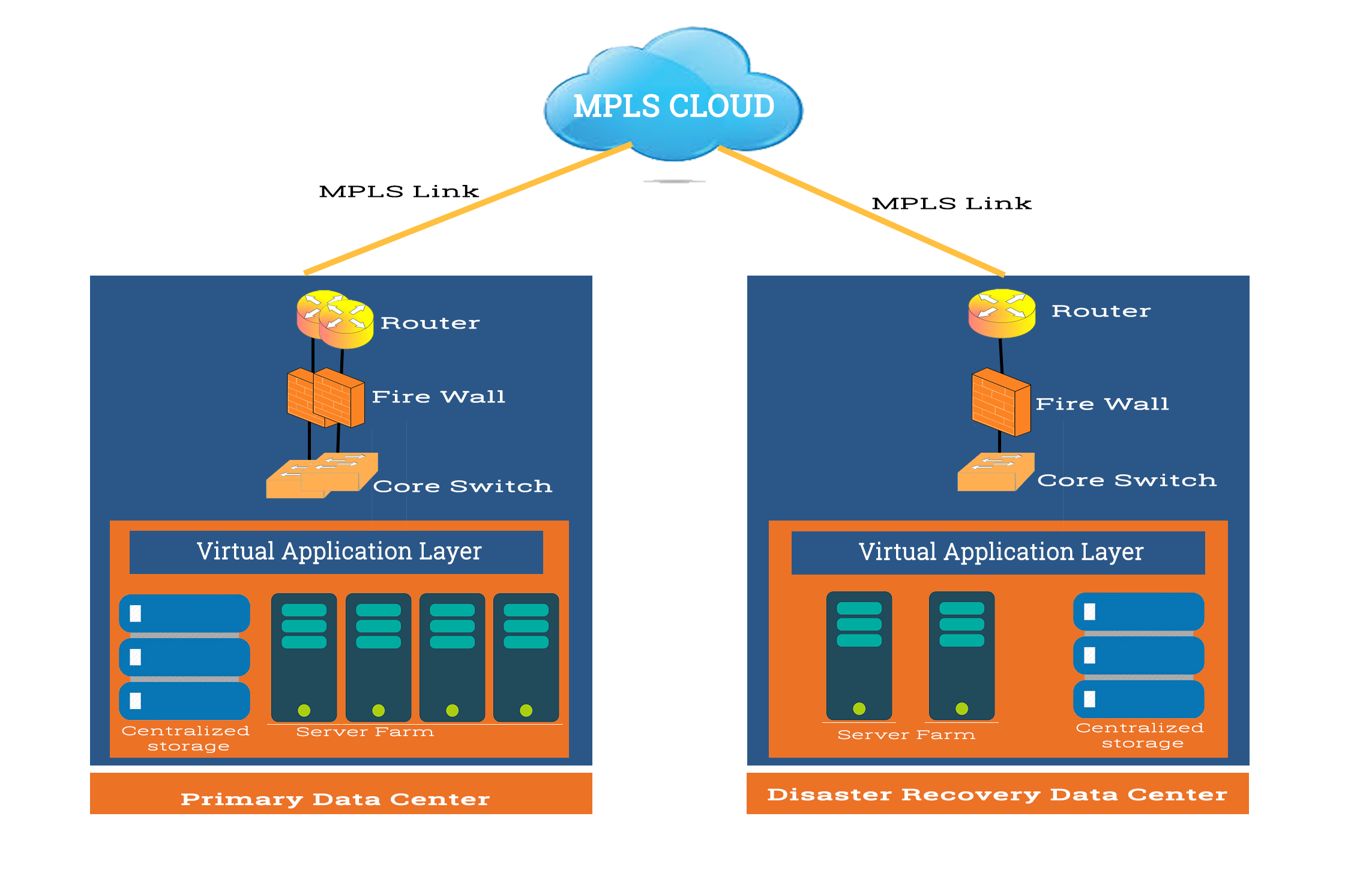
The Government data centre seeks to provide services such as hosting, connectivity and managed IT services. This will enhance service delivery to the public as well as within the Government. Having a Government Data Centre will extend several benefits such as: 1· Consolidated demand and use of resources 2· Reduced cost of maintaining and managing data centre physical infrastructure and associated costs 3· Increased efficiency of data centre ICT assets 4· Improved matching of data centre ICT facilities to business need 5· Standardized ICT infrastructure architectures and sharing of resources. RGoB has a vision to provide some of the government ICT services as cloud services in future for which Government Data center will be built with the capability of providing cloud services. While upcoming BITC Data Center will cater as the core data center, there is no specific plan to build a DR facility but the government is contemplating the possibilities of using Bhutan Telecom (One of the ISPs and Mobile Ops in the country) Data center located in Phuntsholing (Southern Belt of the country) as a Disaster Recovery Site. Business Continuity and Disaster Recovery are closely related practices that describe a Government's preparation for unforeseen risks to continued operations. Disaster recovery is a subset of business continuity and prior to selecting a disaster recovery strategy, a disaster recovery planner first refers to business continuity plan which should indicate the key metrics of recovery point objective (RPO) and recovery time objective (RTO) for various Government services.
Data Architecture
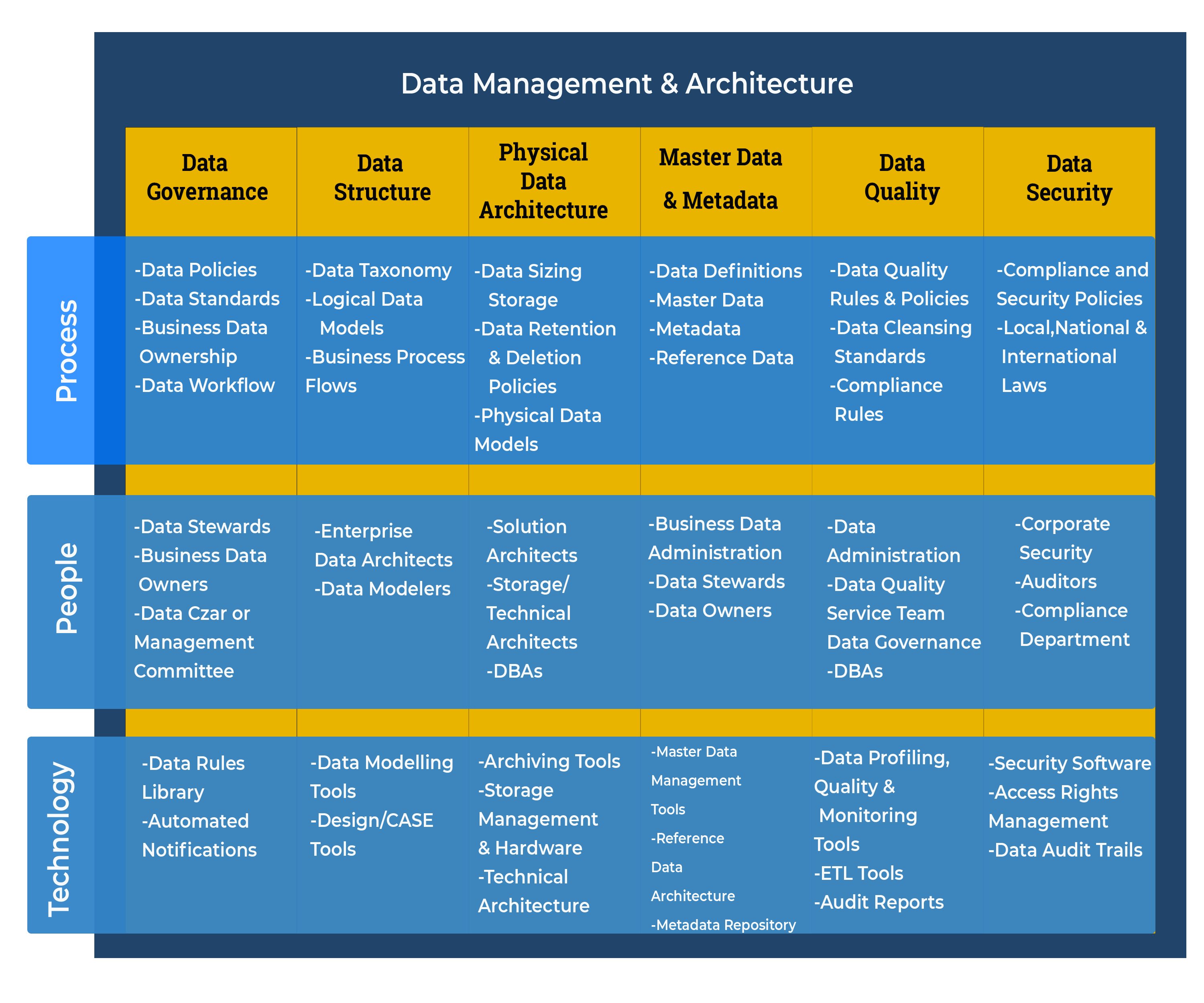
Architecture defines standards to describe, share, structure and classify data. It identifies the common data for data integration and institutes a standard data management practice. The objectives of this reference model is to enable information sharing, data reuse and enhance the accessibility and integrity of the data, with due considerations to data protection.
Data Architecture Components
The Data Architecture Components consist of Data Integration, Data Access, Data Security, Data Lifecycle, Data Migration, and Data Models
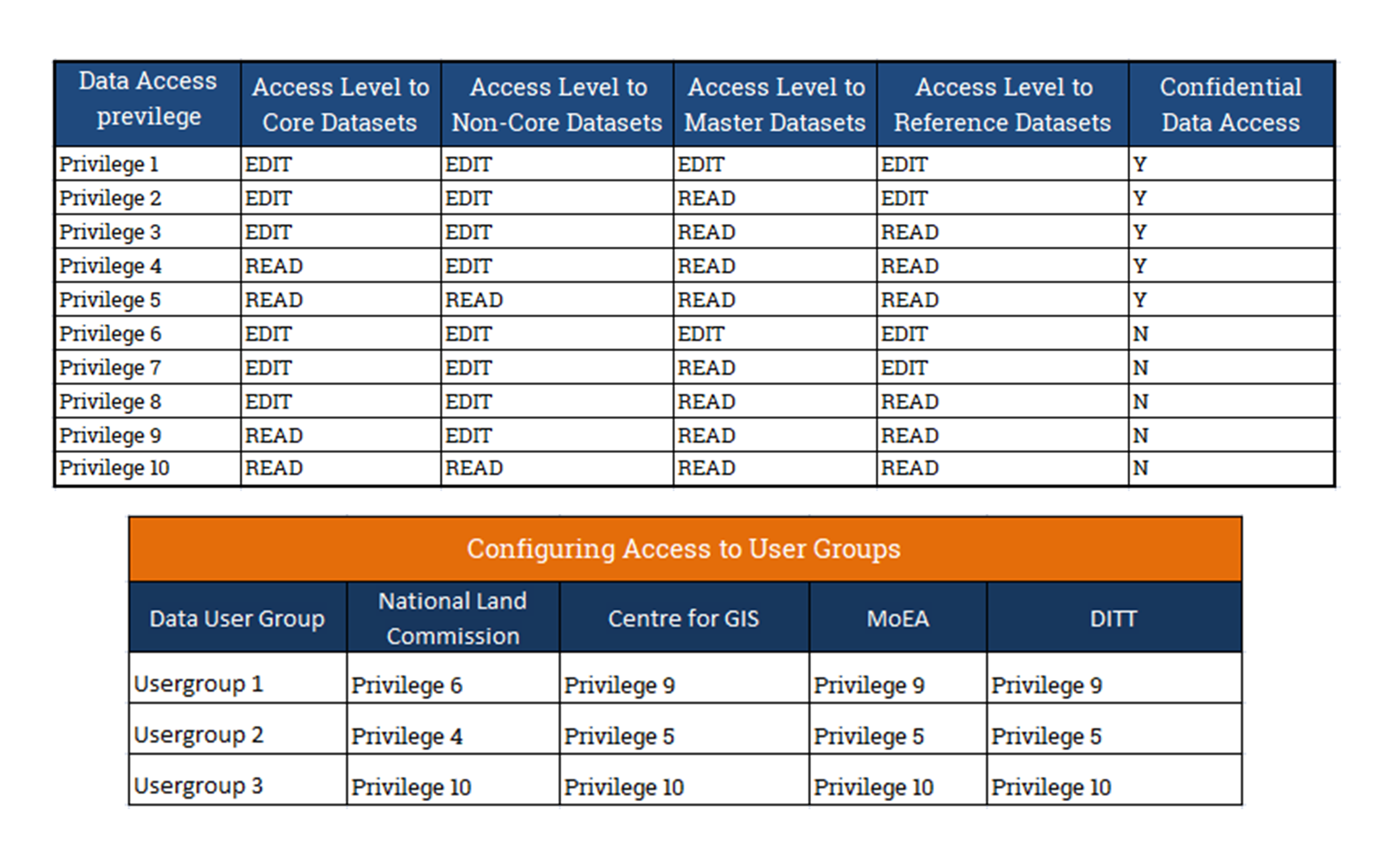
Data Access
Data access model defines data access privileges for business processes that creates, updates and deletes data in an application system. This model ensures that the data in the system is maintained in a consistent manner (i.e., ensures data integrity by applying a set of common rules when adding, changing, and deleting the data. Data Access model also defines the principles on which access rights shall be given to different roles in the database administration. For RGoB, these rights shall be defined precisely in respect of all the Core Datasets and Master Datasets.
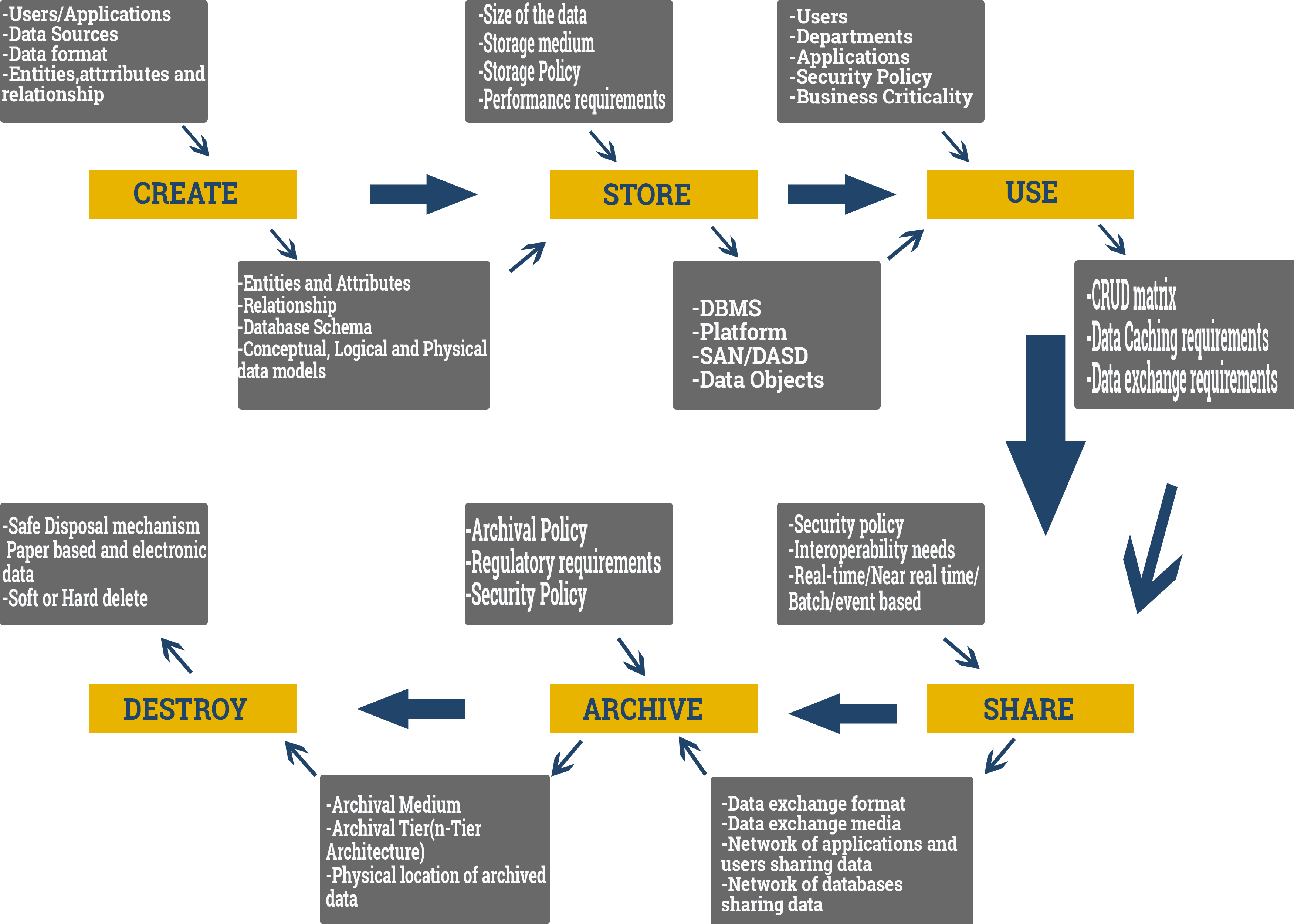
Data Lifecycle
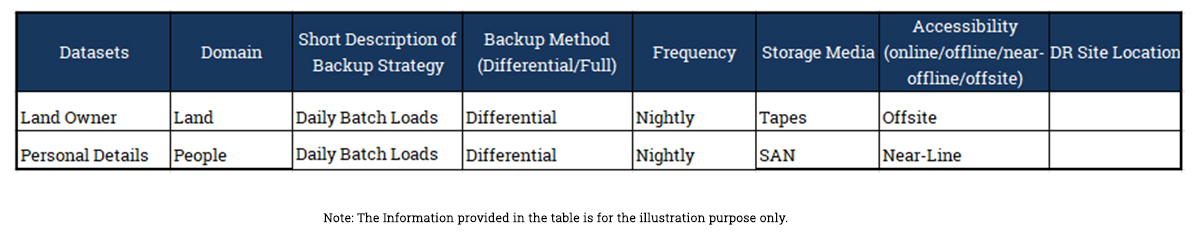
Data Lifecycle management is a policy based approach to manage flow of information systems data throughout its lifecycle: from creation and initial storage to the time when it becomes obsolete and is deleted. The lifecycle crosses different application systems, databases, and storage media. There is a special emphasis and detail in relation to the Core Datasets and Master Datasets from data lifecycle modelling perspective.
Data Migration
When an existing application is replaced, there will be a critical need to migrate data (master, transactional, and reference) to the new application. Data migration model identifies data migration requirements and also provide indicators as to the level of transformation, weeding, and cleansing that will be required to present data in a format that meets the requirements and constraints of the target application. Data Migration process consists of three high level phases: Plan: The planning phase involves determining the requirements of the migration, identifying the current and future environment, and creating and documenting the migration plan. Migrate: This migration phase completes data migration from source to target system. It involves the steps like data assessment, design, build, execution, transition and production. Validate: After migration is completed, the migration process has to be validated using well defined validation methodology. It includes the steps like check lists, preparing test plan, run the test plan and validation of results etc.